Wyszukiwarka

Opis
The dataset contains 87 Scientific papers' abstracts in English randomly chosen from the folowing scientific disciplines: Biomedicine, Life Sciences, Mathematics, Medicine, Science, Humanities, Social Science.
In each text, the named entities are marked. Each name entity is linked to the corresponding Wikipedia if possible. All entities were manually verified by at least three people, which makes the dataset a high-quality gold standard for the evaluation of named entity recognition and linking algorithms.
Each marked entity in the dataset is assigned to one of the following classes:
EVENT - Named hurricanes, battles, wars, sports events, etc.
FAC - Buildings, airports, highways, bridges, etc.
GPE - Countries, cities, states
LANGUAGE - Any named language
LAW - Named documents made into laws.
LOC - Non-GPE locations, mountain ranges, bodies of water
NORP - Nationalities or religious or political groups
ORG - Companies, agencies, institutions, etc.
PERSON - People, including fictional
PRODUCT - Objects, vehicles, foods, etc. (not services)
WORK_OF_ART - Titles of books, songs, etc.
DISEASE - Names of diseases
SUBSTANCE - Natural substances
SPECIE - Species names of animals, plants, viruses, etc.
The marked entities are embedded directly in the textual files using the following syntax:
{{mention content|entity class|Wikipedia target}}
The "mention content" is a fragment of the textual file that was marked, "entity class" is the named entity class, and "Wikipedia target" is the normalized name of the English Wikipedia page describing the entity. If the entity cannot be linked sensibly to any article the target is empty but the second pipe (|) is preserved.
There is a guarantee that the double braces in the texts exist only as marked entity syntax. It allows to process the files using simple regular expression: {{[^{}]*}}
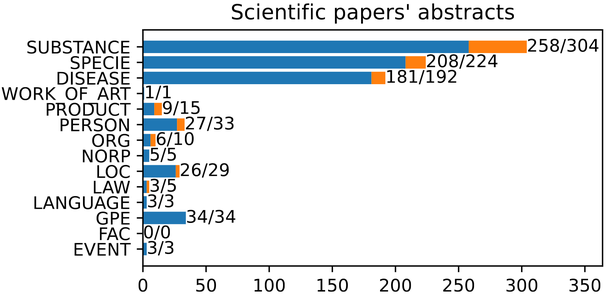
The distribution of datast NER classes, split into separate categories. The first number shows the quantity of linked entities, the second all marked mentions.
Plik z danymi badawczymi
hexmd5(md5(part1)+md5(part2)+...)-{parts_count} gdzie pojedyncza część pliku jest wielkości 512 MBPrzykładowy skrypt do wyliczenia:
https://github.com/antespi/s3md5
Informacje szczegółowe o pliku
- Licencja:
-
 otwiera się w nowej karcie
CC BYUznanie autorstwa
otwiera się w nowej karcie
CC BYUznanie autorstwa
Informacje szczegółowe
- Rok publikacji:
- 2024
- Data zatwierdzenia:
- 2024-05-31
- Data wytworzenia:
- 2024
- Język danych badawczych:
- angielski
- Dyscypliny:
-
- informatyka techniczna i telekomunikacja (Dziedzina nauk inżynieryjno-technicznych)
- DOI:
- Identyfikator DOI 10.34808/pncq-fj33 otwiera się w nowej karcie
- Seria:
- Weryfikacja:
- Politechnika Gdańska
Słowa kluczowe
Powiązane zasoby
Cytuj jako
Autorzy
wyświetlono 109 razy